
Part 1 : Transformers: Introduction to the backbone of Generative AI
- aimlfastrace
- Jan 5
- 4 min read

Updated: Jan 14
Youtube Video: You can refer the video link https://www.youtube.com/watch?v=acUX5uIJYVs for the detailed explanation of the blog.
Understanding Transformers: A Step-by-Step Guide
Welcome to my blog! Today, we're diving into the Transformer model—a groundbreaking architecture that's revolutionising the field of of Natural Language Processing (NLP). In this post, I'll guide you through the essential building blocks of the Transformer. My goal is to break down the complex mechanics of Transformers, making each component clear and easy to understand.
Transformers have revolutionised the field of natural language processing (NLP) and machine learning. Unlike traditional models like Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, which process input sequences sequentially, transformers take advantage of parallel processing. This enables them to handle long-range dependencies in data more efficiently and effectively.
The key component of the Transformer is the attention mechanism, which allows the model to focus on different parts of the input sequence when producing each word of the output sequence. This makes transformers highly suitable for a wide range of tasks, from language translation and text generation to image processing and beyond.
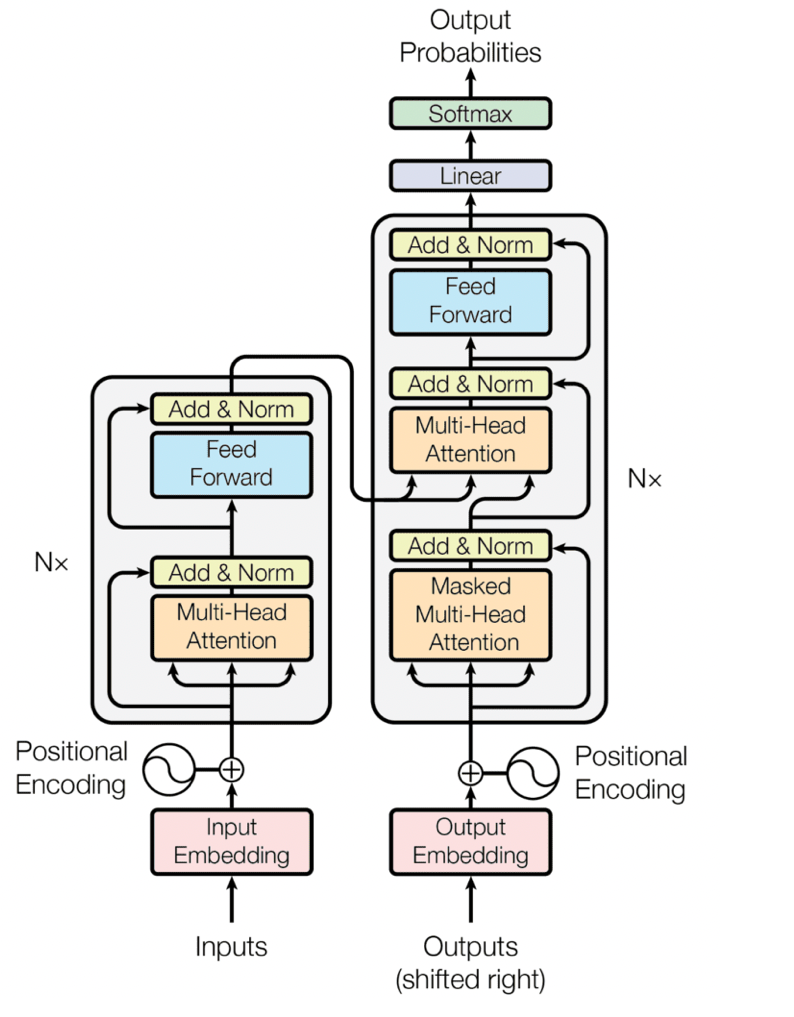
The transformer architecture is the basis for recent well-known models like BERT and GPT-3. Researchers have already applied the transformer architecture in Computer Vision and Reinforcement Learning. So, understanding the transformer architecture is crucial if you want to know where machine learning is heading.
The initial step in any transformer model involves input embeddings and positional encoding. These two components work together to prepare the raw input data so the model can process it effectively.
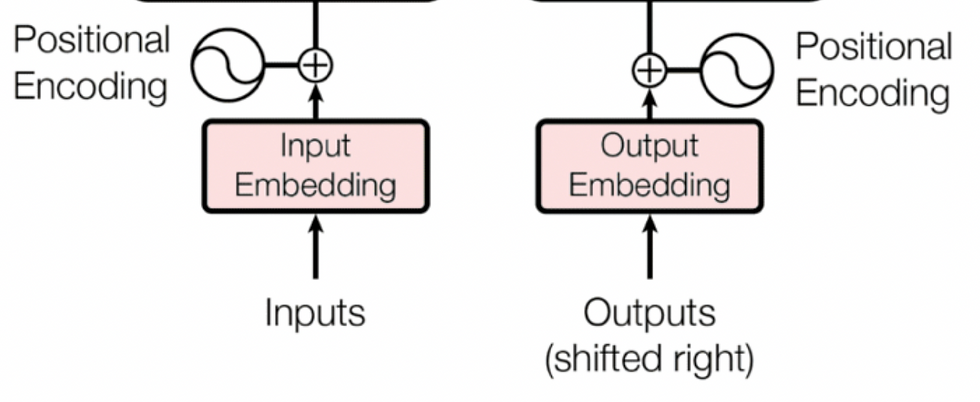
Input embeddings are like a translator for the model. They convert words or tokens from the input sequence into dense vectors of numbers that the transformer can understand. These vectors represent not just the word itself but also capture its meaning and relationship to other words in the context of the sequence.
Positional encoding adds crucial information about the order of words in the sequence. Unlike humans, transformers don’t inherently understand the sequence of data since they process inputs all at once (in parallel). Positional encoding fills this gap, helping the model know which word comes first, second, and so on.
Together, input embeddings and positional encoding act as the foundation for the transformer. Without them, the model wouldn’t be able to grasp the meaning of the input or how the parts of the input relate to each other.
The transformer uses an encoder-decoder architecture. The encoder extracts features from an input sentence, and the decoder uses the features to produce an output sentence The encoder in the transformer consists of multiple encoder blocks. An input sentence goes through the encoder blocks, and the output of the last encoder block becomes the input features to the decoder.
Encoder:
The encoder's role is to process the input sequence and create rich, context-aware representations of it. This is achieved through a stack of identical layers, each consisting of the following components:
Self-Attention Mechanism:
The self-attention mechanism allows the encoder to focus on different parts of the input sequence simultaneously. For example, while processing a word, the model can pay attention to related words anywhere in the sentence. This helps capture relationships and dependencies between words, regardless of their positions.
The attention mechanism computes weighted representations of all tokens relative to each other.
Add & Norm Layers:
After self-attention, the output is added to the input (residual connection) and normalized using layer normalization. This helps stabilize and improve training.
Feed-Forward Neural Network (FFN):
A fully connected feed-forward network is applied to each token independently to transform its representation. This step enhances the model’s ability to learn complex patterns.
Output:
After processing through several encoder layers, the final output is a sequence of fixed-length context-aware vectors, one for each token in the input.
Example of Encoder-Only Models:
BERT (Bidirectional Encoder Representations from Transformers): Used for tasks like text classification, named entity recognition, and question answering.
RoBERTa, DistilBERT, ALBERT: Variants and improvements over BERT.
Decoder:
The decoder generates the output sequence step by step, taking into account the input sequence and the previously generated tokens. It consists of the following components:
Masked Self-Attention Mechanism:
Unlike the encoder's self-attention, the decoder’s self-attention is masked to ensure that the model only attends to previous tokens in the sequence. This is crucial for autoregressive tasks like text generation.
Cross-Attention Mechanism:
This layer connects the decoder to the encoder. It uses the encoder's output to focus on relevant parts of the input sequence while generating the output tokens. This ensures the generated text is contextually aligned with the input.
Add & Norm Layers:
Similar to the encoder, the decoder also uses residual connections and layer normalization to stabilize training.
Feed-Forward Neural Network (FFN):
A fully connected network is applied to transform the token representations further.
Output:
After passing through several decoder layers, the output tokens are generated one by one using a softmax layer that predicts the next token based on probabilities.
Example of Decoder-Only Models:
GPT (Generative Pre-trained Transformer): Used for text generation, summarization, and conversational AI.
GPT-2, GPT-3, ChatGPT: Extensions of GPT with larger scales and capabilities.
Combined Encoder-Decoder Models:
These models use both the encoder and decoder to perform sequence-to-sequence tasks, such as machine translation, summarization, and text generation.
Examples:
Transformer (original): Introduced in the paper "Attention Is All You Need".
T5 (Text-To-Text Transfer Transformer): Converts all NLP tasks into text-to-text problems.
BART (Bidirectional and Auto-Regressive Transformers): Combines a BERT-like encoder with a GPT-like decoder for text generation tasks.
Conclusion:
Transformers have become the model of modern machine learning, revolutionizing how we approach natural language processing and other domains like computer vision and reinforcement learning.
Understanding the mechanics of the Transformer architecture—its building blocks, innovative use of attention, and ability to handle context—provides insights into its versatility and power. This knowledge is crucial for anyone exploring the rapidly evolving field of AI, as it underpins many cutting-edge models like BERT, GPT, T5, and beyond.
With this guide, I hope you now have a clear understanding of the essential components and functionality of transformers. As you continue your journey in AI, mastering these concepts will empower you to innovate and tackle complex challenges across various domains. Thank you for reading, and stay curious!

Comments